John Snow Labs provides a library for delivering safe & effective NLP models.



Project description
LangTest: Deliver Safe & Effective Language Models




Project's Website • Key Features • How To Use • Community Support • Contributing • Mission • License
Project's Website
Take a look at our official page for user documentation and examples: langtest.org
Key Features
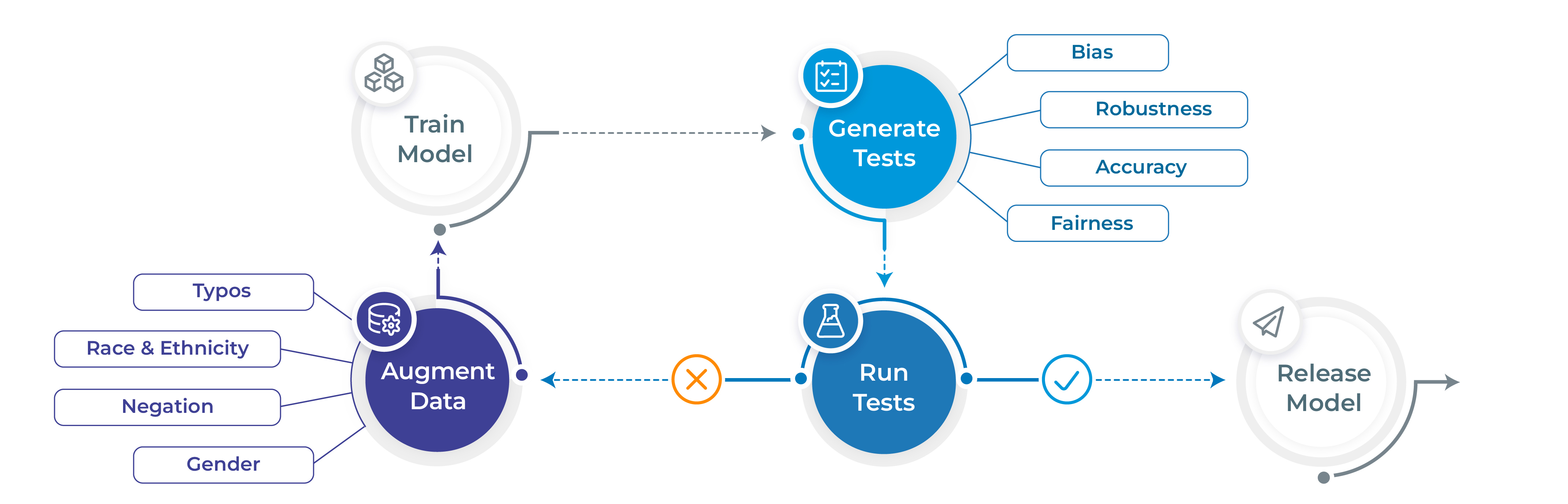
- Generate and execute more than 50 distinct types of tests only with 1 line of code
- Test all aspects of model quality: robustness, bias, representation, fairness and accuracy.
- Automatically augment training data based on test results (for select models)
- Support for popular NLP frameworks for NER, Translation and Text-Classifcation: Spark NLP, Hugging Face & Transformers.
- Support for testing LLMS ( OpenAI, Cohere, AI21, Hugging Face Inference API and Azure-OpenAI LLMs) for question answering, toxicity, clinical-tests, legal-support, factuality, sycophancy and summarization task.
How To Use
# Install langtest
!pip install langtest[transformers]
# Import and create a Harness object
from langtest import Harness
h = Harness(task='ner', model={"model":'dslim/bert-base-NER', "hub":'huggingface'})
# Generate test cases, run them and view a report
h.generate().run().report()
Note For more extended examples of usage and documentation, head over to langtest.org
Community Support
- Slack For live discussion with the LangTest community, join the
#langtestchannel - GitHub For bug reports, feature requests, and contributions
- Discussions To engage with other community members, share ideas, and show off how you use LangTest!
Mission
While there is a lot of talk about the need to train AI models that are safe, robust, and fair - few tools have been made available to data scientists to meet these goals. As a result, the front line of NLP models in production systems reflects a sorry state of affairs.
We propose here an early stage open-source community project that aims to fill this gap, and would love for you to join us on this mission. We aim to build on the foundation laid by previous research such as Ribeiro et al. (2020), Song et al. (2020), Parrish et al. (2021), van Aken et al. (2021) and many others.
John Snow Labs has a full development team allocated to the project and is committed to improving the library for years, as we do with other open-source libraries. Expect frequent releases with new test types, tasks, languages, and platforms to be added regularly. We look forward to working together to make safe, reliable, and responsible NLP an everyday reality.
Comparing Benchmark Datasets: Use Cases and Evaluations
Langtest comes with different datasets to test your models, covering a wide range of use cases and evaluation scenarios.
| Dataset | Use Case | Notebook |
|---|---|---|
| BoolQ | Evaluate the ability of your model to answer boolean questions (yes/no) based on a given passage or context. |  |
| NQ-open | Evaluate the ability of your model to answer open-ended questions based on a given passage or context. | |
| TruthfulQA | Evaluate the model's capability to answer questions accurately and truthfully based on the provided information. | |
| MMLU | Evaluate language understanding models' performance in different domains. It covers 57 subjects across STEM, the humanities, the social sciences, and more. | |
| NarrativeQA | Evaluate your model's ability to comprehend and answer questions about long and complex narratives, such as stories or articles. | |
| HellaSwag | Evaluate your model's ability in completions of sentences. | |
| Quac | Evaluate your model's ability to answer questions given a conversational context, focusing on dialogue-based question-answering. | |
| OpenBookQA | Evaluate your model's ability to answer questions that require complex reasoning and inference based on general knowledge, similar to an "open-book" exam. | |
| BBQ | Evaluate how your model responds to questions in the presence of social biases against protected classes across various social dimensions. Assess biases in model outputs with both under-informative and adequately informative contexts, aiming to promote fair and unbiased question-answering models. | |
| XSum | Evaluate your model's ability to generate concise and informative summaries for long articles with the XSum dataset. It consists of articles and corresponding one-sentence summaries, offering a valuable benchmark for text summarization models. | |
| Real Toxicity Prompts | Evaluate your model's accuracy in recognizing and handling toxic language with the Real Toxicity Prompts dataset. It contains real-world prompts from online platforms, ensuring robustness in NLP models to maintain safe environments. | |
| LogiQA | Evaluate your model's accuracy on Machine Reading Comprehension with Logical Reasoning questions. | |
| BigBench Abstract narrative understanding | Evaluate your model's performance in selecting the most relevant proverb for a given narrative. | |
| BigBench Causal Judgment | Evaluate your model's performance in measuring the ability to reason about cause and effect. | |
| BigBench DisambiguationQA | Evaluate your model's performance on determining the interpretation of sentences containing ambiguous pronoun references. | |
| BigBench DisflQA | Evaluate your model's performance in picking the correct answer span from the context given the disfluent question. | |
| ASDiv | Evaluate your model's ability answer questions based on Math Word Problems. | |
| Legal-QA | Evaluate your model's performance on legal-qa datasets | |
| CommonsenseQA | Evaluate your model's performance on the CommonsenseQA dataset, which demands a diverse range of commonsense knowledge to accurately predict the correct answers in a multiple-choice question answering format. | |
| SIQA | Evaluate your model's performance by assessing its accuracy in understanding social situations, inferring the implications of actions, and comparing human-curated and machine-generated answers. | |
| PIQA | Evaluate your model's performance on the PIQA dataset, which tests its ability to reason about everyday physical situations through multiple-choice questions, contributing to AI's understanding of real-world interactions. | |
| MultiLexSum | Evaluate your model's ability to generate concise and informative summaries for legal case contexts from the Multi-LexSum dataset, with a focus on comprehensively capturing essential themes and key details within the legal narratives. | |
Note For usage and documentation, head over to langtest.org
Blog
You can check out the following langtest articles:
| Blog | Description |
|---|---|
| Automatically Testing for Demographic Bias in Clinical Treatment Plans Generated by Large Language Models | Helps in understanding and testing demographic bias in clinical treatment plans generated by LLM. |
| LangTest: Unveiling & Fixing Biases with End-to-End NLP Pipelines | The end-to-end language pipeline in LangTest empowers NLP practitioners to tackle biases in language models with a comprehensive, data-driven, and iterative approach. |
| Beyond Accuracy: Robustness Testing of Named Entity Recognition Models with LangTest | While accuracy is undoubtedly crucial, robustness testing takes natural language processing (NLP) models evaluation to the next level by ensuring that models can perform reliably and consistently across a wide array of real-world conditions. |
| Elevate Your NLP Models with Automated Data Augmentation for Enhanced Performance | In this article, we discuss how automated data augmentation may supercharge your NLP models and improve their performance and how we do that using LangTest. |
| Mitigating Gender-Occupational Stereotypes in AI: Evaluating Models with the Wino Bias Test through Langtest Library | In this article, we discuss how we can test the "Wino Bias” using LangTest. It specifically refers to testing biases arising from gender-occupational stereotypes. |
| Automating Responsible AI: Integrating Hugging Face and LangTest for More Robust Models | In this article, we have explored the integration between Hugging Face, your go-to source for state-of-the-art NLP models and datasets, and LangTest, your NLP pipeline’s secret weapon for testing and optimization. |
Note To checkout all blogs, head over to Blogs
Contributing
We welcome all sorts of contributions:
- Ideas
- Feedback
- Documentation
- Bug reports
- Development and testing
Feel free to clone the repo and submit pull-requests! You can also contribute by simply opening an issue or discussion in this repo.
Contributors
We would like to acknowledge all contributors of this open-source community project.

License
LangTest is released under the Apache License 2.0, which guarantees commercial use, modification, distribution, patent use, private use and sets limitations on trademark use, liability and warranty.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file langtest-1.7.0rc2.tar.gz.
File metadata
- Download URL: langtest-1.7.0rc2.tar.gz
- Upload date:
- Size: 17.4 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.5.1 CPython/3.8.9 Windows/10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
81bec5b51a82d3b7b97c48785a6c974f6a6ed2c055326b0e8285a65bda5c55fd
|
|
| MD5 |
88a5757b7342d0a63380490ec4ed2944
|
|
| BLAKE2b-256 |
6bb7287e4c8c86382f82a13ccbc5dd34cb9e52481f8b0cc1e1323ba513c51261
|
File details
Details for the file langtest-1.7.0rc2-py3-none-any.whl.
File metadata
- Download URL: langtest-1.7.0rc2-py3-none-any.whl
- Upload date:
- Size: 17.6 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.5.1 CPython/3.8.9 Windows/10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a86ffa777508fd7859c5f6046264e82649933eff346563df0d15aa073d5b0587
|
|
| MD5 |
c26b9420215af9423f768aa4c360dc66
|
|
| BLAKE2b-256 |
b3ed5954cbb38538c93959810616f3c63e4c8f7006b54cb2060cd2e8f6df4236
|







