MLflow is an open source platform for the complete machine learning lifecycle

Project description
📣 This is the mlflow-skinny package, a lightweight MLflow package without SQL storage, server, UI, or data science dependencies.
Additional dependencies can be installed to leverage the full feature set of MLflow. For example:
- To use the
mlflow.sklearncomponent of MLflow Models, installscikit-learn,numpyandpandas. - To use SQL-based metadata storage, install
sqlalchemy,alembic, andsqlparse. - To use serving-based features, install
flaskandpandas.
Note: When using mlflow-skinny, set the tracking URI to your remote MLflow server:
export MLFLOW_TRACKING_URI="http://your-mlflow-server:5000"

The Open Source AI Engineering Platform
MLflow is the largest open source AI engineering platform for agents, LLMs, and ML models. MLflow enables teams of all sizes to debug, evaluate, monitor, and optimize production-quality AI applications while controlling costs and managing access to models and data. With over 30 million monthly downloads, thousands of organizations rely on MLflow each day to ship AI to production with confidence.
MLflow's comprehensive feature set for agents and LLM applications includes production-grade observability, evaluation, prompt management, an AI Gateway for managing costs and model access, and more. Learn more at MLflow for LLMs and Agents.
For machine learning (ML) model development, MLflow provides experiment tracking, model evaluation capabilities, a production model registry, and model deployment tools.






🚀 Installation
To install the MLflow Python package, run the following command:
pip install mlflow
📦 Core Components
MLflow is the only platform that provides a unified solution for all your AI/ML needs, including LLMs, Agents, Deep Learning, and traditional machine learning.
💡 For AI Agent / LLM Application Developers

🔍 Tracing / Observability Trace the internal states of your LLM/agentic applications for debugging quality issues and monitoring performance with ease. Getting Started → |
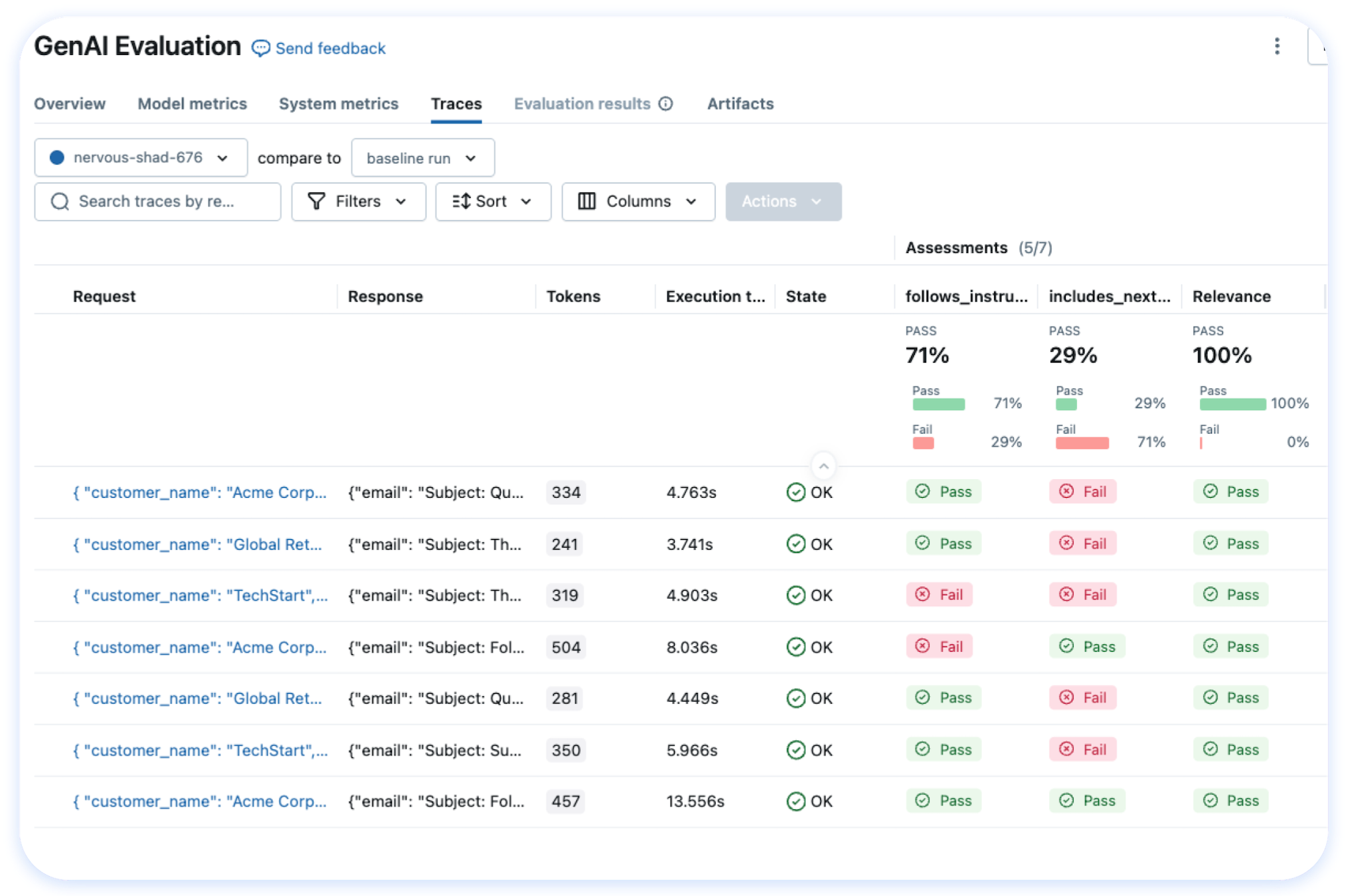
📊 LLM Evaluation A suite of automated model evaluation tools, seamlessly integrated with experiment tracking to compare across multiple versions. Getting Started → |
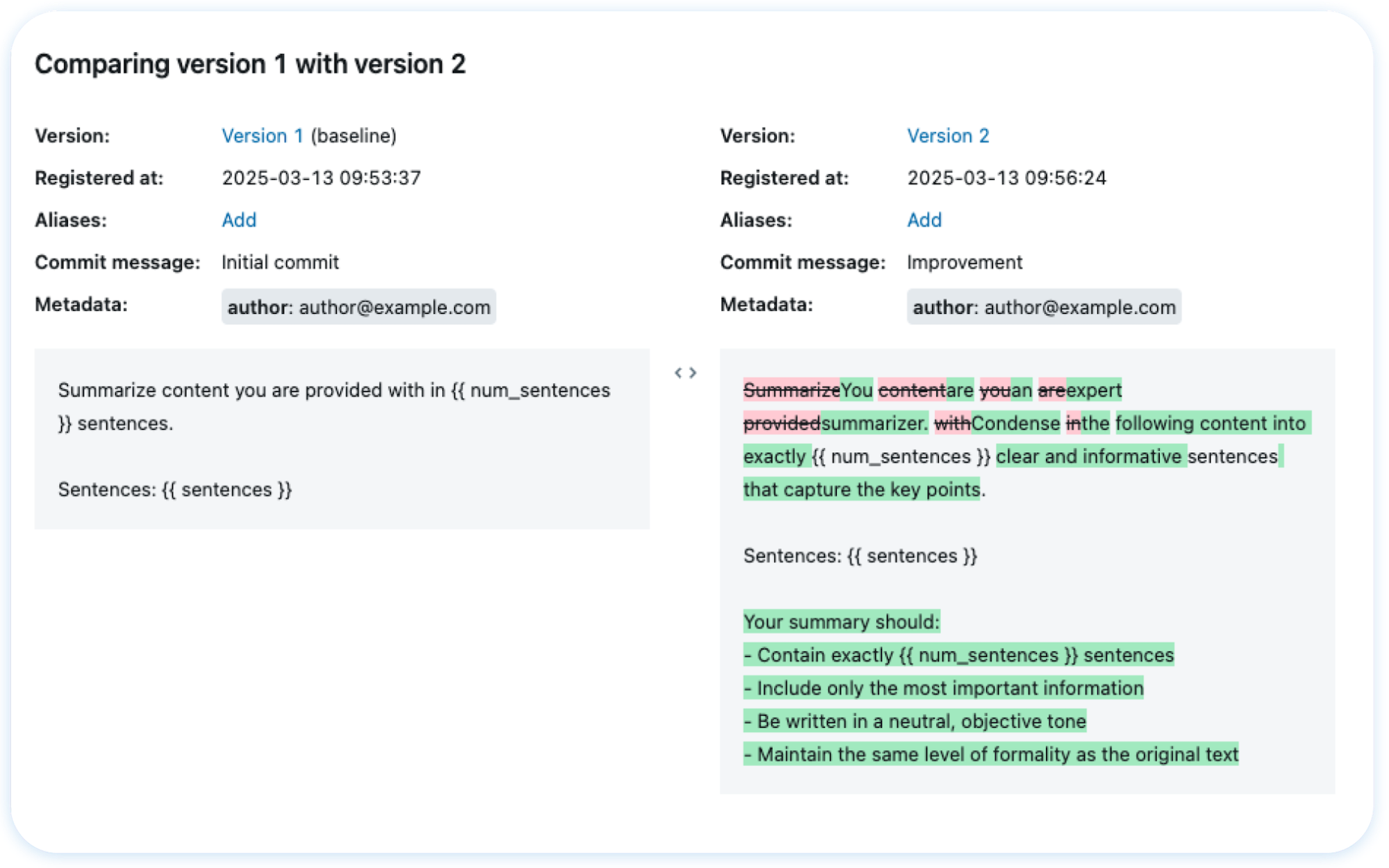
🤖 Prompt Management Version, track, and reuse prompts across your organization, helping maintain consistency and improve collaboration in prompt development. Automatically optimize prompts using data-driven algorithms instead of manual trial-and-error. Getting Started → |
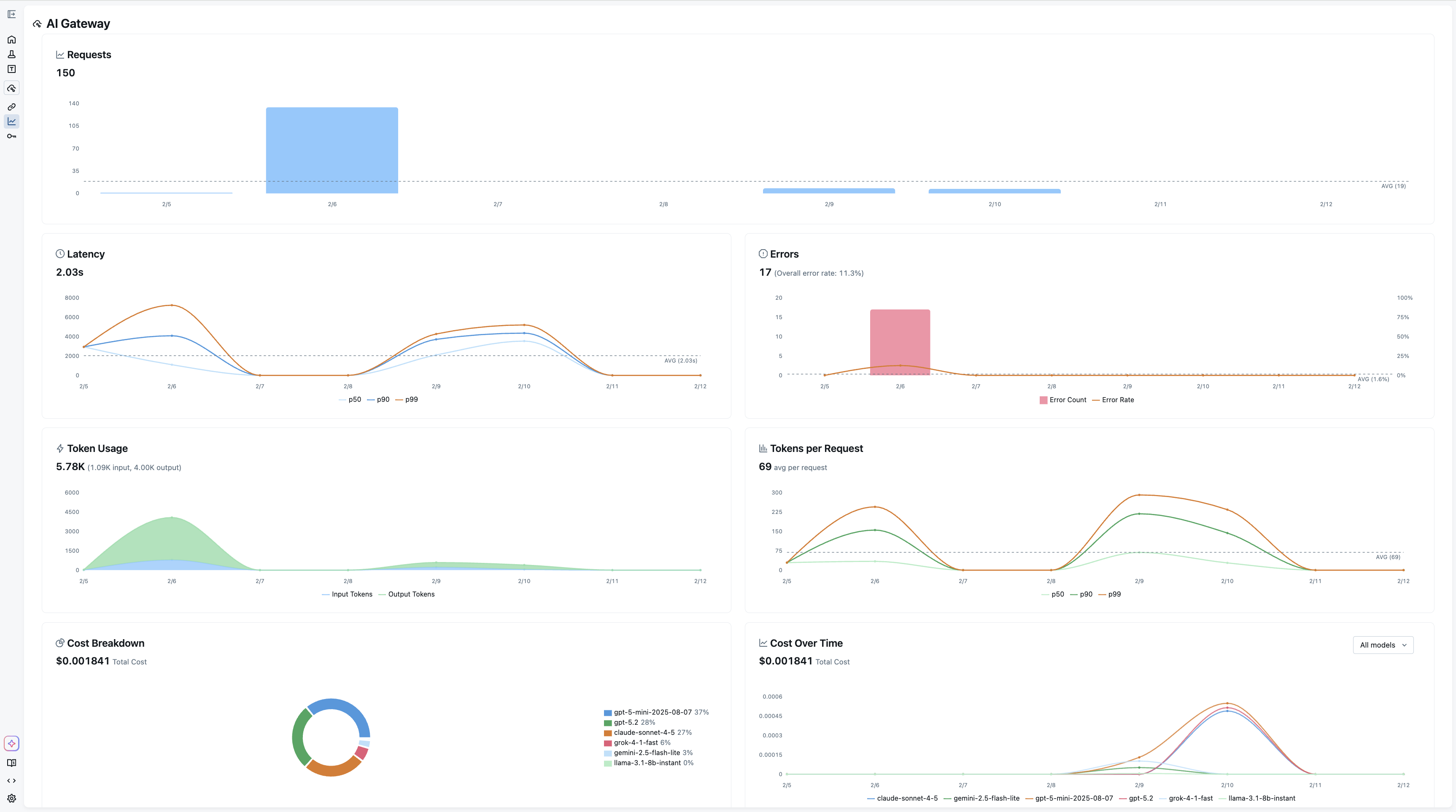
🌐 AI Gateway Route requests to any LLM provider through a secure proxy, with built-in credential management, cost tracking, guardrails, traffic splitting for A/B testing, automatic failover, and beyond. Getting Started → |
🎓 For Data Scientists
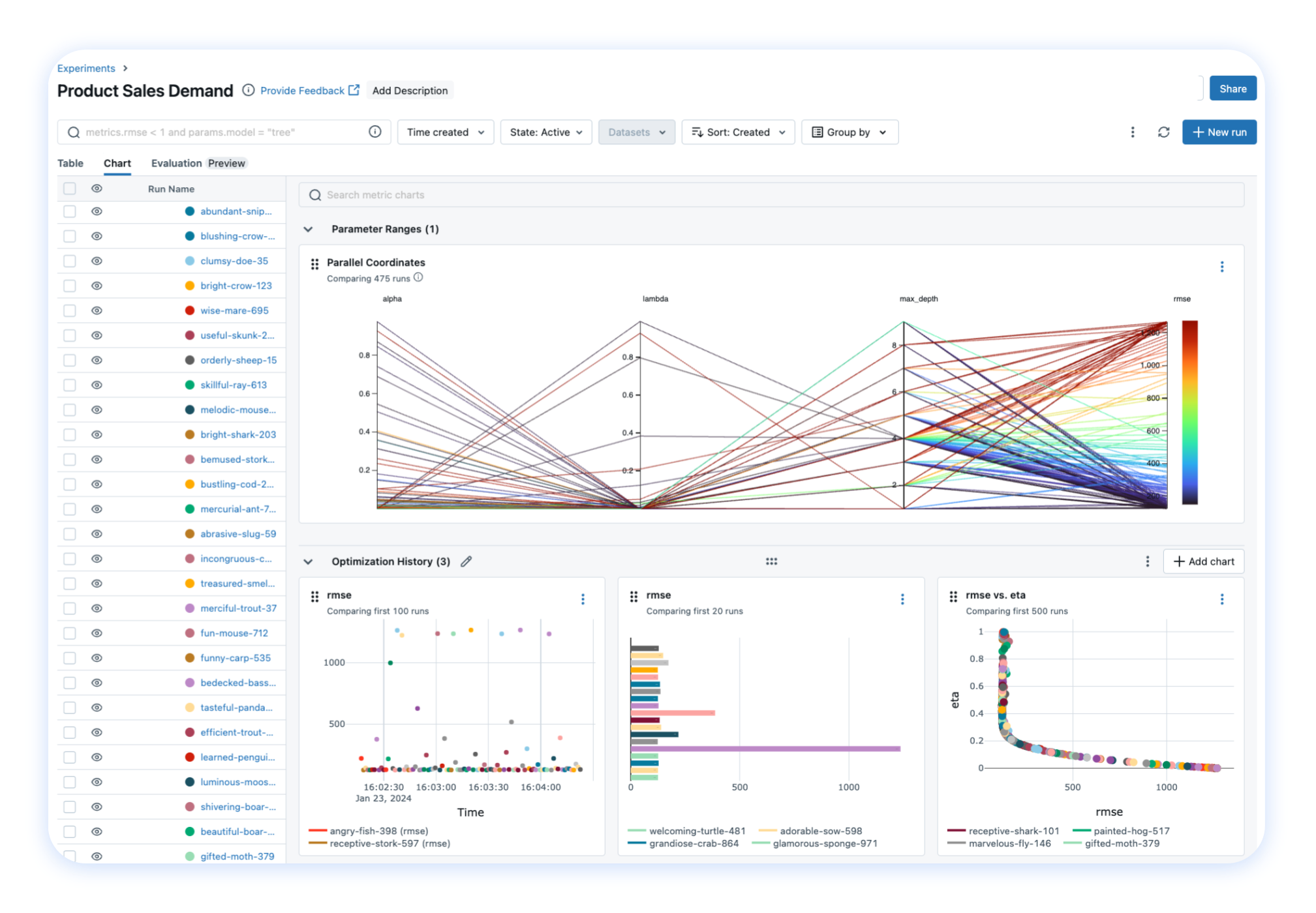
📝 Experiment Tracking Track your models, parameters, metrics, and evaluation results in ML experiments and compare them using an interactive UI. Getting Started → |
|
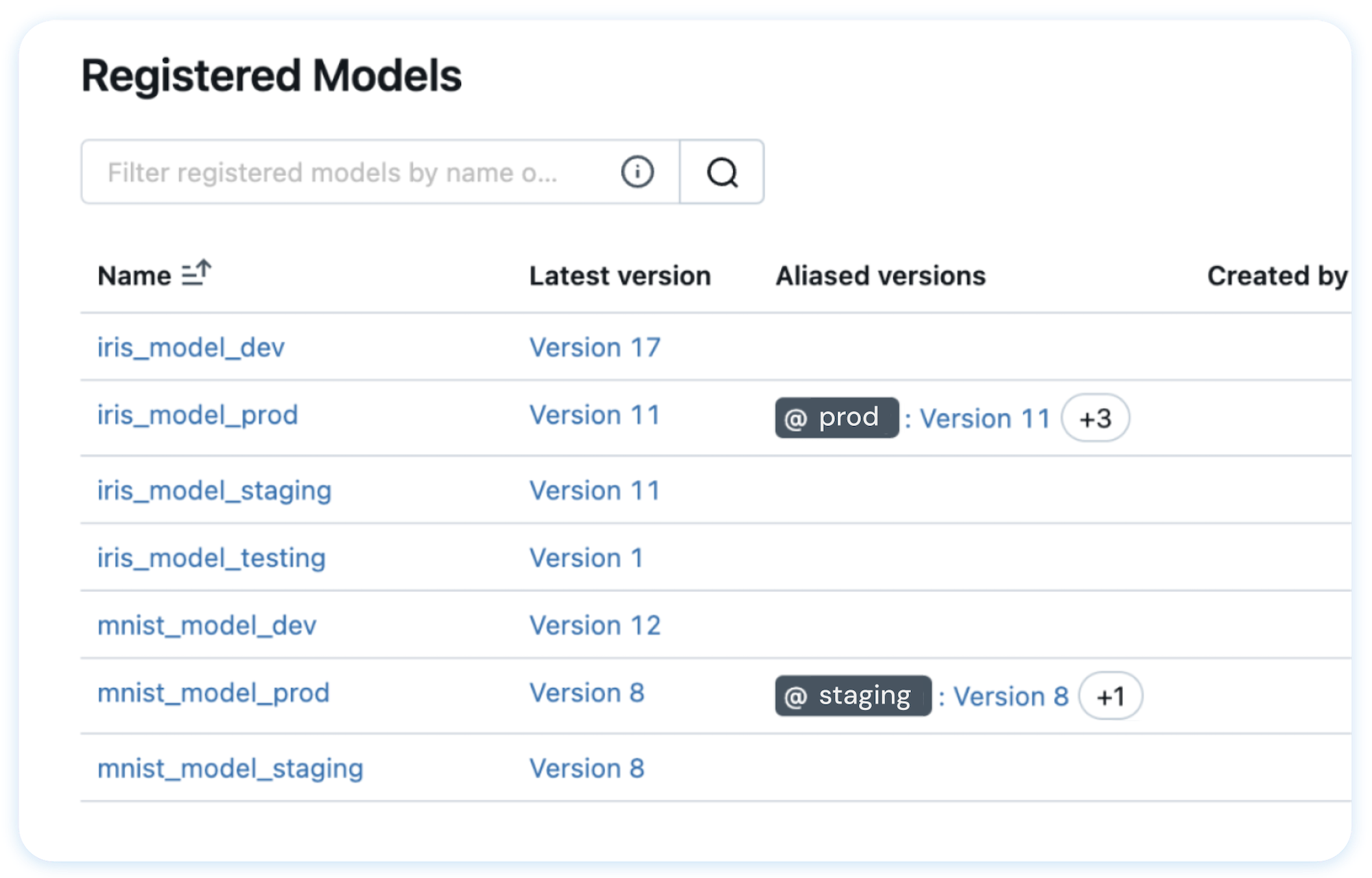
💾 Model Registry A centralized model store designed to collaboratively manage the full lifecycle and deployment of machine learning models. Getting Started → |
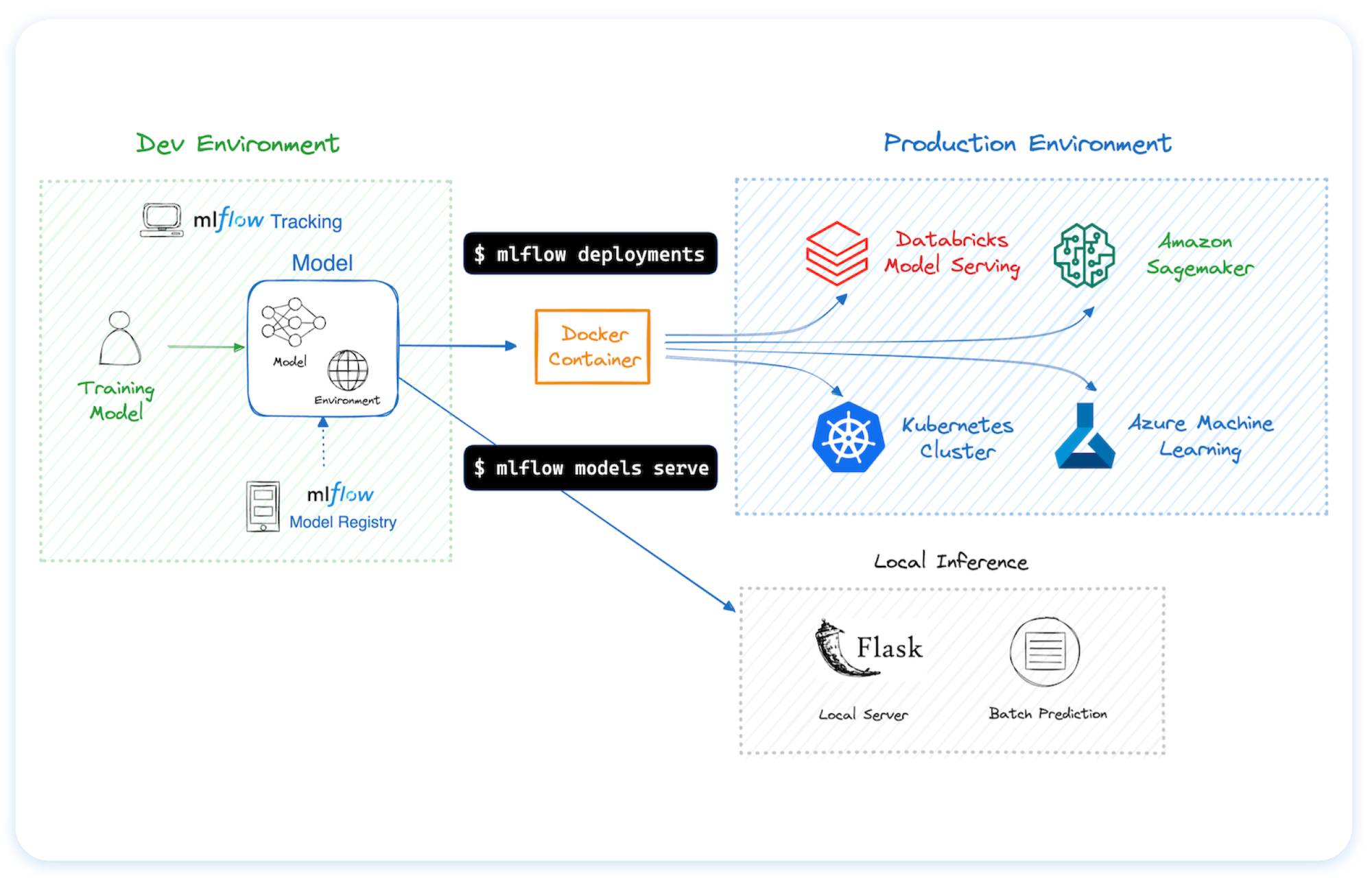
🚀 Deployment Tools for seamless model deployment to batch and real-time scoring on platforms like Docker, Kubernetes, Azure ML, and AWS SageMaker. Getting Started → |
🌐 Hosting MLflow Anywhere

You can run MLflow in many different environments, including local machines, on-premise servers, and cloud infrastructure.
Trusted by thousands of organizations, MLflow is now offered as a managed service by most major cloud providers:
For hosting MLflow on your own infrastructure, please refer to this guidance.
🗣️ Supported Programming Languages
🔗 Integrations
MLflow is natively integrated with popular AI agent frameworks and machine learning libraries. MLflow supports all LLM providers, AI tools and programming languages.

Usage Examples
Tracing (Observability) (Doc)
MLflow Tracing provides observability for various AI agent and LLM application libraries such as OpenAI, LangChain, LlamaIndex, DSPy, AutoGen, and more. To enable auto-tracing, call mlflow.xyz.autolog() before running your models. Refer to the documentation for customization and manual instrumentation.
import mlflow
from openai import OpenAI
# Enable tracing for OpenAI
mlflow.openai.autolog()
# Query OpenAI LLM normally
response = OpenAI().chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "Hi!"}],
temperature=0.1,
)
Then navigate to the "Traces" tab in the MLflow UI to find the trace records for the OpenAI query.
Evaluating LLMs, Prompts, and Agents (Doc)
The following example runs automatic evaluation for question-answering tasks with several built-in metrics.
import os
import openai
import mlflow
from mlflow.genai.scorers import Correctness, Guidelines
client = openai.OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# 1. Define a simple QA dataset
dataset = [
{
"inputs": {"question": "Can MLflow manage prompts?"},
"expectations": {"expected_response": "Yes!"},
},
{
"inputs": {"question": "Can MLflow create a taco for my lunch?"},
"expectations": {"expected_response": "No, unfortunately, MLflow is not a taco maker."},
},
]
# 2. Define a prediction function to generate responses
def predict_fn(question: str) -> str:
response = client.chat.completions.create(
model="gpt-4o-mini", messages=[{"role": "user", "content": question}]
)
return response.choices[0].message.content
# 3. Run the evaluation
results = mlflow.genai.evaluate(
data=dataset,
predict_fn=predict_fn,
scorers=[
# Built-in LLM judge
Correctness(),
# Custom criteria using LLM judge
Guidelines(name="is_english", guidelines="The answer must be in English"),
],
)
Navigate to the "Evaluations" tab in the MLflow UI to find the evaluation results.
Tracking Model Training (Doc)
The following example trains a simple regression model with scikit-learn, while enabling MLflow's autologging feature for experiment tracking.
import mlflow
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
# Enable MLflow's automatic experiment tracking for scikit-learn
mlflow.sklearn.autolog()
# Load the training dataset
db = load_diabetes()
X_train, X_test, y_train, y_test = train_test_split(db.data, db.target)
rf = RandomForestRegressor(n_estimators=100, max_depth=6, max_features=3)
# MLflow triggers logging automatically upon model fitting
rf.fit(X_train, y_train)
Once the above code finishes, run the following command in a separate terminal and access the MLflow UI via the printed URL. An MLflow Run should be automatically created, which tracks the training dataset, hyperparameters, performance metrics, the trained model, dependencies, and even more.
mlflow server
💭 Support
- For help or questions about MLflow usage (e.g. "how do I do X?") visit the documentation.
- In the documentation, you can ask the question to our AI-powered chat bot. Click on the "Ask AI" button at the right bottom.
- Join the virtual events like office hours and meetups.
- To report a bug, file a documentation issue, or submit a feature request, please open a GitHub issue.
- For release announcements and other discussions, please subscribe to our mailing list (mlflow-users@googlegroups.com) or join us on Slack.
🤝 Contributing
We happily welcome contributions to MLflow!
- Submit bug reports and feature requests
- Contribute for good-first-issues and help-wanted
- Writing about MLflow and sharing your experience
Please see our contribution guide to learn more about contributing to MLflow.
⭐️ Star History

✏️ Citation
If you use MLflow in your research, please cite it using the "Cite this repository" button at the top of the GitHub repository page, which will provide you with citation formats including APA and BibTeX.
👥 Core Members
MLflow is currently maintained by the following core members with significant contributions from hundreds of exceptionally talented community members.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mlflow_skinny-3.11.0rc0.tar.gz.
File metadata
- Download URL: mlflow_skinny-3.11.0rc0.tar.gz
- Upload date:
- Size: 2.6 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.24
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1b453c8f7402ce37cebcc12a3098d4af5a9e9a2aa377e58bd971e0364a604a29
|
|
| MD5 |
ebdf7f227117a987f38458366245064b
|
|
| BLAKE2b-256 |
ad031760baae5cacba36e16e077345e631e31a13c4e99837ecebdecfd974406c
|
File details
Details for the file mlflow_skinny-3.11.0rc0-py3-none-any.whl.
File metadata
- Download URL: mlflow_skinny-3.11.0rc0-py3-none-any.whl
- Upload date:
- Size: 3.1 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.24
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
70a21649a54e538cf6668705f212d775cce0b3554edd300fd7dacdc6c0b485f2
|
|
| MD5 |
f5795e8c2fa349e4de02dfda66483847
|
|
| BLAKE2b-256 |
7eca143c9692dab64a897797fd38dd34eb65045718c6b74c668a722a9ee75bc2
|







