Multi-class confusion matrix library in Python



Project description







Table of contents
- Overview
- Installation
- Usage
- Document
- Try PyCM in Your Browser
- Issues & Bug Reports
- Todo
- Outputs
- Dependencies
- Contribution
- Acknowledgments
- References
- Cite
- Authors
- License
- Show Your Support
- Changelog
- Code of Conduct
Overview
PyCM is a multi-class confusion matrix library written in Python that supports both input data vectors and direct matrix, and a proper tool for post-classification model evaluation that supports most classes and overall statistics parameters. PyCM is the swiss-army knife of confusion matrices, targeted mainly at data scientists that need a broad array of metrics for predictive models and accurate evaluation of a large variety of classifiers.
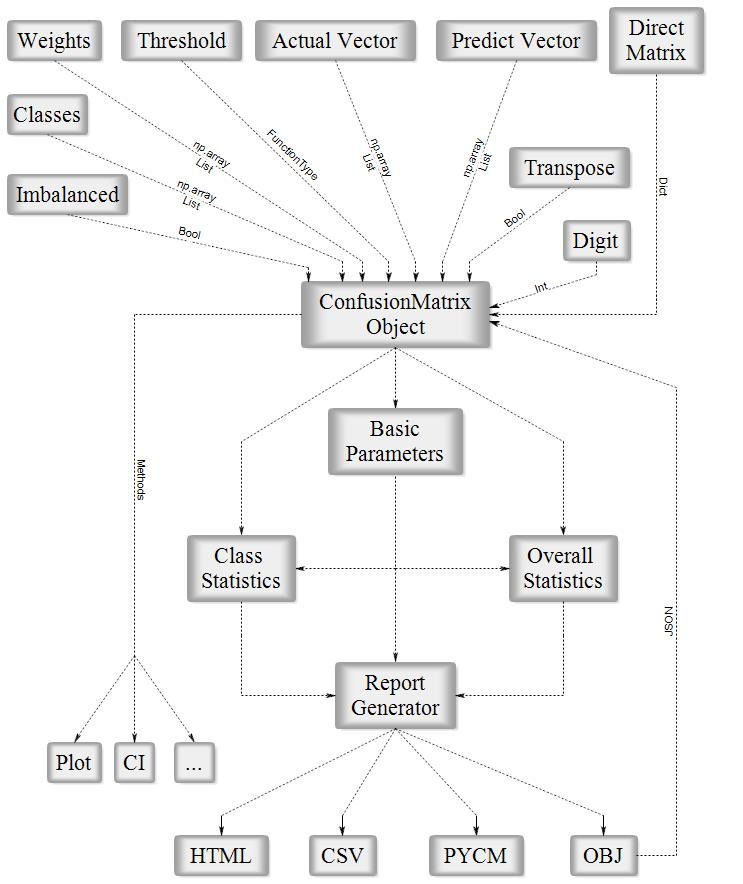
Fig1. ConfusionMatrix Block Diagram
| Open Hub |  |
| PyPI Counter |  |
| Github Stars |  |
| Branch | master | dev |
| CI |  |
 |
| Code Quality |  |
 |
 |
Installation
⚠️ PyCM 2.4 is the last version to support Python 2.7 & Python 3.4
⚠️ Plotting capability requires Matplotlib (>= 3.0.0) or Seaborn (>= 0.9.1)
Source code
- Download Version 3.6 or Latest Source
- Run
pip install -r requirements.txtorpip3 install -r requirements.txt(Need root access) - Run
python3 setup.py installorpython setup.py install(Need root access)
PyPI
- Check Python Packaging User Guide
- Run
pip install pycm==3.6orpip3 install pycm==3.6(Need root access)
Conda
- Check Conda Managing Package
- Update Conda using
conda update conda(Need root access) - Run
conda install -c sepandhaghighi pycm(Need root access)
Easy install
- Run
easy_install --upgrade pycm(Need root access)
MATLAB
- Download and install MATLAB (>=8.5, 64/32 bit)
- Download and install Python3.x (>=3.5, 64/32 bit)
- Select
Add to PATHoption - Select
Install pipoption
- Select
- Run
pip install pycmorpip3 install pycm(Need root access) - Configure Python interpreter
>> pyversion PYTHON_EXECUTABLE_FULL_PATH
- Visit MATLAB Examples
Usage
From vector
>>> from pycm import *
>>> y_actu = [2, 0, 2, 2, 0, 1, 1, 2, 2, 0, 1, 2]
>>> y_pred = [0, 0, 2, 1, 0, 2, 1, 0, 2, 0, 2, 2]
>>> cm = ConfusionMatrix(actual_vector=y_actu, predict_vector=y_pred)
>>> cm.classes
[0, 1, 2]
>>> cm.table
{0: {0: 3, 1: 0, 2: 0}, 1: {0: 0, 1: 1, 2: 2}, 2: {0: 2, 1: 1, 2: 3}}
>>> cm.print_matrix()
Predict 0 1 2
Actual
0 3 0 0
1 0 1 2
2 2 1 3
>>> cm.print_normalized_matrix()
Predict 0 1 2
Actual
0 1.0 0.0 0.0
1 0.0 0.33333 0.66667
2 0.33333 0.16667 0.5
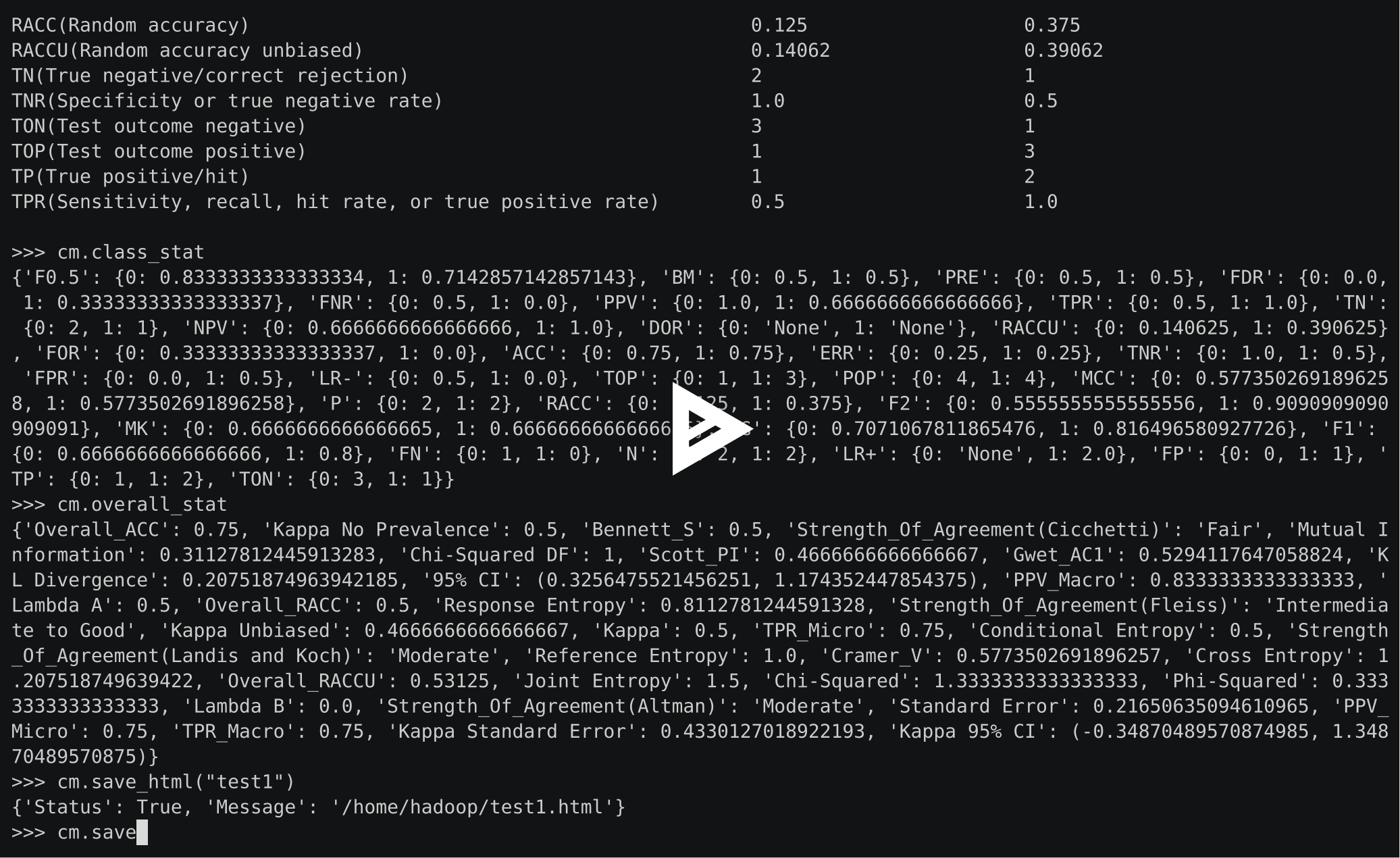
>>> cm.stat(summary=True)
Overall Statistics :
ACC Macro 0.72222
F1 Macro 0.56515
FPR Macro 0.22222
Kappa 0.35484
Overall ACC 0.58333
PPV Macro 0.56667
SOA1(Landis & Koch) Fair
TPR Macro 0.61111
Zero-one Loss 5
Class Statistics :
Classes 0 1 2
ACC(Accuracy) 0.83333 0.75 0.58333
AUC(Area under the ROC curve) 0.88889 0.61111 0.58333
AUCI(AUC value interpretation) Very Good Fair Poor
F1(F1 score - harmonic mean of precision and sensitivity) 0.75 0.4 0.54545
FN(False negative/miss/type 2 error) 0 2 3
FP(False positive/type 1 error/false alarm) 2 1 2
FPR(Fall-out or false positive rate) 0.22222 0.11111 0.33333
N(Condition negative) 9 9 6
P(Condition positive or support) 3 3 6
POP(Population) 12 12 12
PPV(Precision or positive predictive value) 0.6 0.5 0.6
TN(True negative/correct rejection) 7 8 4
TON(Test outcome negative) 7 10 7
TOP(Test outcome positive) 5 2 5
TP(True positive/hit) 3 1 3
TPR(Sensitivity, recall, hit rate, or true positive rate) 1.0 0.33333 0.5
Direct CM
>>> from pycm import *
>>> cm2 = ConfusionMatrix(matrix={"Class1": {"Class1": 1, "Class2":2}, "Class2": {"Class1": 0, "Class2": 5}})
>>> cm2
pycm.ConfusionMatrix(classes: ['Class1', 'Class2'])
>>> cm2.classes
['Class1', 'Class2']
>>> cm2.print_matrix()
Predict Class1 Class2
Actual
Class1 1 2
Class2 0 5
>>> cm2.print_normalized_matrix()
Predict Class1 Class2
Actual
Class1 0.33333 0.66667
Class2 0.0 1.0
>>> cm2.stat(summary=True)
Overall Statistics :
ACC Macro 0.75
F1 Macro 0.66667
FPR Macro 0.33333
Kappa 0.38462
Overall ACC 0.75
PPV Macro 0.85714
SOA1(Landis & Koch) Fair
TPR Macro 0.66667
Zero-one Loss 2
Class Statistics :
Classes Class1 Class2
ACC(Accuracy) 0.75 0.75
AUC(Area under the ROC curve) 0.66667 0.66667
AUCI(AUC value interpretation) Fair Fair
F1(F1 score - harmonic mean of precision and sensitivity) 0.5 0.83333
FN(False negative/miss/type 2 error) 2 0
FP(False positive/type 1 error/false alarm) 0 2
FPR(Fall-out or false positive rate) 0.0 0.66667
N(Condition negative) 5 3
P(Condition positive or support) 3 5
POP(Population) 8 8
PPV(Precision or positive predictive value) 1.0 0.71429
TN(True negative/correct rejection) 5 1
TON(Test outcome negative) 7 1
TOP(Test outcome positive) 1 7
TP(True positive/hit) 1 5
TPR(Sensitivity, recall, hit rate, or true positive rate) 0.33333 1.0
matrix()andnormalized_matrix()renamed toprint_matrix()andprint_normalized_matrix()inversion 1.5
Activation threshold
threshold is added in version 0.9 for real value prediction.
For more information visit Example3
Load from file
file is added in version 0.9.5 in order to load saved confusion matrix with .obj format generated by save_obj method.
For more information visit Example4
Sample weights
sample_weight is added in version 1.2
For more information visit Example5
Transpose
transpose is added in version 1.2 in order to transpose input matrix (only in Direct CM mode)
Relabel
relabel method is added in version 1.5 in order to change ConfusionMatrix classnames.
>>> cm.relabel(mapping={0:"L1",1:"L2",2:"L3"})
>>> cm
pycm.ConfusionMatrix(classes: ['L1', 'L2', 'L3'])
Position
position method is added in version 2.8 in order to find the indexes of observations in predict_vector which made TP, TN, FP, FN.
>>> cm.position()
{0: {'FN': [], 'FP': [0, 7], 'TP': [1, 4, 9], 'TN': [2, 3, 5, 6, 8, 10, 11]}, 1: {'FN': [5, 10], 'FP': [3], 'TP': [6], 'TN': [0, 1, 2, 4, 7, 8, 9, 11]}, 2: {'FN': [0, 3, 7], 'FP': [5, 10], 'TP': [2, 8, 11], 'TN': [1, 4, 6, 9]}}
To array
to_array method is added in version 2.9 in order to returns the confusion matrix in the form of a NumPy array. This can be helpful to apply different operations over the confusion matrix for different purposes such as aggregation, normalization, and combination.
>>> cm.to_array()
array([[3, 0, 0],
[0, 1, 2],
[2, 1, 3]])
>>> cm.to_array(normalized=True)
array([[1. , 0. , 0. ],
[0. , 0.33333, 0.66667],
[0.33333, 0.16667, 0.5 ]])
>>> cm.to_array(normalized=True,one_vs_all=True, class_name="L1")
array([[1. , 0. ],
[0.22222, 0.77778]])
Combine
combine method is added in version 3.0 in order to merge two confusion matrices. This option will be useful in mini-batch learning.
>>> cm_combined = cm2.combine(cm3)
>>> cm_combined.print_matrix()
Predict Class1 Class2
Actual
Class1 2 4
Class2 0 10
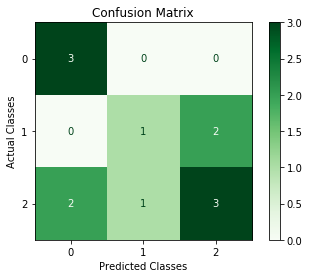
Plot
plot method is added in version 3.0 in order to plot a confusion matrix using Matplotlib or Seaborn.
>>> cm.plot()

>>> from matplotlib import pyplot as plt
>>> cm.plot(cmap=plt.cm.Greens,number_label=True,plot_lib="matplotlib")
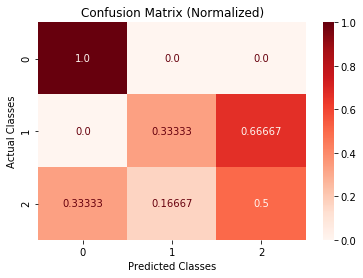
>>> cm.plot(cmap=plt.cm.Reds,normalized=True,number_label=True,plot_lib="seaborn")
Online help
online_help function is added in version 1.1 in order to open each statistics definition in web browser
>>> from pycm import online_help
>>> online_help("J")
>>> online_help("SOA1(Landis & Koch)")
>>> online_help(2)
- List of items are available by calling
online_help()(without argument) - If PyCM website is not available, set
alt_link = True(new inversion 2.4)
Parameter recommender
This option has been added in version 1.9 to recommend the most related parameters considering the characteristics of the input dataset.
The suggested parameters are selected according to some characteristics of the input such as being balance/imbalance and binary/multi-class.
All suggestions can be categorized into three main groups: imbalanced dataset, binary classification for a balanced dataset, and multi-class classification for a balanced dataset.
The recommendation lists have been gathered according to the respective paper of each parameter and the capabilities which had been claimed by the paper.
>>> cm.imbalance
False
>>> cm.binary
False
>>> cm.recommended_list
['MCC', 'TPR Micro', 'ACC', 'PPV Macro', 'BCD', 'Overall MCC', 'Hamming Loss', 'TPR Macro', 'Zero-one Loss', 'ERR', 'PPV Micro', 'Overall ACC']
is_imbalanced parameter has been added in version 3.3, so the user can indicate whether the concerned dataset is imbalanced or not. As long as the user does not provide any information in this regard, the automatic detection algorithm will be used.
>>> cm = ConfusionMatrix(y_actu, y_pred, is_imbalanced = True)
>>> cm.imbalance
True
>>> cm = ConfusionMatrix(y_actu, y_pred, is_imbalanced = False)
>>> cm.imbalance
False
Compare
In version 2.0, a method for comparing several confusion matrices is introduced. This option is a combination of several overall and class-based benchmarks. Each of the benchmarks evaluates the performance of the classification algorithm from good to poor and give them a numeric score. The score of good and poor performances are 1 and 0, respectively.
After that, two scores are calculated for each confusion matrices, overall and class-based. The overall score is the average of the score of six overall benchmarks which are Landis & Koch, Fleiss, Altman, Cicchetti, Cramer, and Matthews. In the same manner, the class-based score is the average of the score of six class-based benchmarks which are Positive Likelihood Ratio Interpretation, Negative Likelihood Ratio Interpretation, Discriminant Power Interpretation, AUC value Interpretation, Matthews Correlation Coefficient Interpretation and Yule's Q Interpretation. It should be noticed that if one of the benchmarks returns none for one of the classes, that benchmarks will be eliminated in total averaging. If the user sets weights for the classes, the averaging over the value of class-based benchmark scores will transform to a weighted average.
If the user sets the value of by_class boolean input True, the best confusion matrix is the one with the maximum class-based score. Otherwise, if a confusion matrix obtains the maximum of both overall and class-based scores, that will be reported as the best confusion matrix, but in any other case, the compared object doesn’t select the best confusion matrix.
>>> cm2 = ConfusionMatrix(matrix={0:{0:2,1:50,2:6},1:{0:5,1:50,2:3},2:{0:1,1:7,2:50}})
>>> cm3 = ConfusionMatrix(matrix={0:{0:50,1:2,2:6},1:{0:50,1:5,2:3},2:{0:1,1:55,2:2}})
>>> cp = Compare({"cm2":cm2,"cm3":cm3})
>>> print(cp)
Best : cm2
Rank Name Class-Score Overall-Score
1 cm2 0.50278 0.425
2 cm3 0.33611 0.33056
>>> cp.best
pycm.ConfusionMatrix(classes: [0, 1, 2])
>>> cp.sorted
['cm2', 'cm3']
>>> cp.best_name
'cm2'
Acceptable data types
ConfusionMatrix
actual_vector: pythonlistor numpyarrayof any stringable objectspredict_vector: pythonlistor numpyarrayof any stringable objectsmatrix:dictdigit:intthreshold:FunctionType (function or lambda)file:File objectsample_weight: pythonlistor numpyarrayof numberstranspose:boolclasses: pythonlistis_imbalanced:bool
- Run
help(ConfusionMatrix)forConfusionMatrixobject details
Compare
cm_dict: pythondictofConfusionMatrixobject (str:ConfusionMatrix)by_class:boolclass_weight: pythondictof class weights (class_name:float)class_benchmark_weight: pythondictof class benchmark weights (class_benchmark_name:float)overall_benchmark_weight: pythondictof overall benchmark weights (overall_benchmark_name:float)digit:int
- Run
help(Compare)forCompareobject details
For more information visit here
Try PyCM in your browser!
PyCM can be used online in interactive Jupyter Notebooks via the Binder or Colab services! Try it out now! :

- Check
ExamplesinDocumentfolder
Issues & bug reports
- Fill an issue and describe it. We'll check it ASAP!
- Please complete the issue template
- Discord : https://discord.com/invite/zqpU2b3J3f
- Website : https://www.pycm.io
- Mailing List : https://mail.python.org/mailman3/lists/pycm.python.org/
- Email : info@pycm.io
Outputs
Dependencies
| master | dev |
 |
 |
Acknowledgments
NLnet foundation has supported the PyCM project from version 3.6 to 4.0 through the NGI Assure Fund. This fund is set up by NLnet foundation with funding from the European Commission's Next Generation Internet program, administered by DG Communications Networks, Content, and Technology under grant agreement No 957073.


References
1- J. R. Landis and G. G. Koch, "The measurement of observer agreement for categorical data," biometrics, pp. 159-174, 1977.
2- D. M. Powers, "Evaluation: from precision, recall and F-measure to ROC, informedness, markedness and correlation," arXiv preprint arXiv:2010.16061, 2020.
3- C. Sammut and G. I. Webb, Encyclopedia of machine learning. Springer Science & Business Media, 2011.
4- J. L. Fleiss, "Measuring nominal scale agreement among many raters," Psychological bulletin, vol. 76, no. 5, p. 378, 1971.
5- D. G. Altman, Practical statistics for medical research. CRC press, 1990.
6- K. L. Gwet, "Computing inter-rater reliability and its variance in the presence of high agreement," British Journal of Mathematical and Statistical Psychology, vol. 61, no. 1, pp. 29-48, 2008.
7- W. A. Scott, "Reliability of content analysis: The case of nominal scale coding," Public opinion quarterly, pp. 321-325, 1955.
8- E. M. Bennett, R. Alpert, and A. Goldstein, "Communications through limited-response questioning," Public Opinion Quarterly, vol. 18, no. 3, pp. 303-308, 1954.
9- D. V. Cicchetti, "Guidelines, criteria, and rules of thumb for evaluating normed and standardized assessment instruments in psychology," Psychological assessment, vol. 6, no. 4, p. 284, 1994.
10- R. B. Davies, "Algorithm AS 155: The distribution of a linear combination of χ2 random variables," Applied Statistics, pp. 323-333, 1980.
11- S. Kullback and R. A. Leibler, "On information and sufficiency," The annals of mathematical statistics, vol. 22, no. 1, pp. 79-86, 1951.
12- L. A. Goodman and W. H. Kruskal, "Measures of association for cross classifications, IV: Simplification of asymptotic variances," Journal of the American Statistical Association, vol. 67, no. 338, pp. 415-421, 1972.
13- L. A. Goodman and W. H. Kruskal, "Measures of association for cross classifications III: Approximate sampling theory," Journal of the American Statistical Association, vol. 58, no. 302, pp. 310-364, 1963.
14- T. Byrt, J. Bishop, and J. B. Carlin, "Bias, prevalence and kappa," Journal of clinical epidemiology, vol. 46, no. 5, pp. 423-429, 1993.
15- M. Shepperd, D. Bowes, and T. Hall, "Researcher bias: The use of machine learning in software defect prediction," IEEE Transactions on Software Engineering, vol. 40, no. 6, pp. 603-616, 2014.
16- X. Deng, Q. Liu, Y. Deng, and S. Mahadevan, "An improved method to construct basic probability assignment based on the confusion matrix for classification problem," Information Sciences, vol. 340, pp. 250-261, 2016.
17- J.-M. Wei, X.-J. Yuan, Q.-H. Hu, and S.-Q. Wang, "A novel measure for evaluating classifiers," Expert Systems with Applications, vol. 37, no. 5, pp. 3799-3809, 2010.
18- I. Kononenko and I. Bratko, "Information-based evaluation criterion for classifier's performance," Machine learning, vol. 6, no. 1, pp. 67-80, 1991.
19- R. Delgado and J. D. Núnez-González, "Enhancing confusion entropy as measure for evaluating classifiers," in The 13th International Conference on Soft Computing Models in Industrial and Environmental Applications, 2018: Springer, pp. 79-89.
20- J. Gorodkin, "Comparing two K-category assignments by a K-category correlation coefficient," Computational biology and chemistry, vol.28, no. 5-6, pp. 367-374, 2004.
21- C. O. Freitas, J. M. De Carvalho, J. Oliveira, S. B. Aires, and R. Sabourin, "Confusion matrix disagreement for multiple classifiers," in Iberoamerican Congress on Pattern Recognition, 2007: Springer, pp. 387-396.
22- P. Branco, L. Torgo, and R. P. Ribeiro, "Relevance-based evaluation metrics for multi-class imbalanced domains," in Pacific-Asia Conference on Knowledge Discovery and Data Mining, 2017: Springer, pp. 698-710.
23- D. Ballabio, F. Grisoni, and R. Todeschini, "Multivariate comparison of classification performance measures," Chemometrics and Intelligent Laboratory Systems, vol. 174, pp. 33-44, 2018.
24- J. Cohen, "A coefficient of agreement for nominal scales," Educational and psychological measurement, vol. 20, no. 1, pp. 37-46, 1960.
25- S. Siegel, "Nonparametric statistics for the behavioral sciences," 1956.
26- H. Cramér, Mathematical methods of statistics. Princeton university press, 1999.
27- B. W. Matthews, "Comparison of the predicted and observed secondary structure of T4 phage lysozyme," Biochimica et Biophysica Acta (BBA)-Protein Structure, vol. 405, no. 2, pp. 442-451, 1975.
28- J. A. Swets, "The relative operating characteristic in psychology: a technique for isolating effects of response bias finds wide use in the study of perception and cognition," Science, vol. 182, no. 4116, pp. 990-1000, 1973.
29- P. Jaccard, "Étude comparative de la distribution florale dans une portion des Alpes et des Jura," Bull Soc Vaudoise Sci Nat, vol. 37, pp. 547-579, 1901.
30- T. M. Cover and J. A. Thomas, Elements of Information Theory. John Wiley & Sons, 2012.
31- E. S. Keeping, Introduction to statistical inference. Courier Corporation, 1995.
32- V. Sindhwani, P. Bhattacharya, and S. Rakshit, "Information theoretic feature crediting in multiclass support vector machines," in Proceedings of the 2001 SIAM International Conference on Data Mining, 2001: SIAM, pp. 1-18.
33- M. Bekkar, H. K. Djemaa, and T. A. Alitouche, "Evaluation measures for models assessment over imbalanced data sets," J Inf Eng Appl, vol. 3, no. 10, 2013.
34- W. J. Youden, "Index for rating diagnostic tests," Cancer, vol. 3, no. 1, pp. 32-35, 1950.
35- S. Brin, R. Motwani, J. D. Ullman, and S. Tsur, "Dynamic itemset counting and implication rules for market basket data," in Proceedings of the 1997 ACM SIGMOD international conference on Management of data, 1997, pp. 255-264.
36- S. Raschka, "MLxtend: Providing machine learning and data science utilities and extensions to Python's scientific computing stack," Journal of open source software, vol. 3, no. 24, p. 638, 2018.
37- J. R. Bray and J. T. Curtis, "An ordination of the upland forest communities of southern Wisconsin," Ecological monographs, vol. 27, no. 4, pp. 325-349, 1957.
38- J. L. Fleiss, J. Cohen, and B. S. Everitt, "Large sample standard errors of kappa and weighted kappa," Psychological bulletin, vol. 72, no. 5, p. 323, 1969.
39- M. Felkin, "Comparing classification results between n-ary and binary problems," in Quality Measures in Data Mining: Springer, 2007, pp. 277-301.
40- R. Ranawana and V. Palade, "Optimized precision-a new measure for classifier performance evaluation," in 2006 IEEE International Conference on Evolutionary Computation, 2006: IEEE, pp. 2254-2261.
41- V. García, R. A. Mollineda, and J. S. Sánchez, "Index of balanced accuracy: A performance measure for skewed class distributions," in Iberian conference on pattern recognition and image analysis, 2009: Springer, pp. 441-448.
42- P. Branco, L. Torgo, and R. P. Ribeiro, "A survey of predictive modeling on imbalanced domains," ACM Computing Surveys (CSUR), vol. 49, no. 2, pp. 1-50, 2016.
43- K. Pearson, "Notes on Regression and Inheritance in the Case of Two Parents," in Proceedings of the Royal Society of London, p. 240-242, 1895.
44- W. J. Conover, Practical nonparametric statistics. John Wiley & Sons, 1998.
45- G. U. Yule, "On the methods of measuring association between two attributes," Journal of the Royal Statistical Society, vol. 75, no. 6, pp. 579-652, 1912.
46- R. Batuwita and V. Palade, "A new performance measure for class imbalance learning. application to bioinformatics problems," in 2009 International Conference on Machine Learning and Applications, 2009: IEEE, pp. 545-550.
47- D. K. Lee, "Alternatives to P value: confidence interval and effect size," Korean journal of anesthesiology, vol. 69, no. 6, p. 555, 2016.
48- M. A. Raslich, R. J. Markert, and S. A. Stutes, "Selecting and interpreting diagnostic tests," Biochemia Medica, vol. 17, no. 2, pp. 151-161, 2007.
49- D. E. Hinkle, W. Wiersma, and S. G. Jurs, Applied statistics for the behavioral sciences. Houghton Mifflin College Division, 2003.
50- A. Maratea, A. Petrosino, and M. Manzo, "Adjusted F-measure and kernel scaling for imbalanced data learning," Information Sciences, vol. 257, pp. 331-341, 2014.
51- L. Mosley, "A balanced approach to the multi-class imbalance problem," 2013.
52- M. Vijaymeena and K. Kavitha, "A survey on similarity measures in text mining," Machine Learning and Applications: An International Journal, vol. 3, no. 2, pp. 19-28, 2016.
53- Y. Otsuka, "The faunal character of the Japanese Pleistocene marine Mollusca, as evidence of climate having become colder during the Pleistocene in Japan," Biogeograph Soc Japan, vol. 6, no. 16, pp. 165-170, 1936.
54- A. Tversky, "Features of similarity," Psychological review, vol. 84, no. 4, p. 327, 1977.
55- K. Boyd, K. H. Eng, and C. D. Page, "Area under the precision-recall curve: point estimates and confidence intervals," in Joint European conference on machine learning and knowledge discovery in databases, 2013: Springer, pp. 451-466.
56- J. Davis and M. Goadrich, "The relationship between Precision-Recall and ROC curves," in Proceedings of the 23rd international conference on Machine learning, 2006, pp. 233-240.
57- M. Kuhn, "Building predictive models in R using the caret package," J Stat Softw, vol. 28, no. 5, pp. 1-26, 2008.
58- V. Labatut and H. Cherifi, "Accuracy measures for the comparison of classifiers," arXiv preprint arXiv:1207.3790, 2012.
59- S. Wallis, "Binomial confidence intervals and contingency tests: mathematical fundamentals and the evaluation of alternative methods," Journal of Quantitative Linguistics, vol. 20, no. 3, pp. 178-208, 2013.
60- D. Altman, D. Machin, T. Bryant, and M. Gardner, Statistics with confidence: confidence intervals and statistical guidelines. John Wiley & Sons, 2013.
61- J. A. Hanley and B. J. McNeil, "The meaning and use of the area under a receiver operating characteristic (ROC) curve," Radiology, vol. 143, no. 1, pp. 29-36, 1982.
62- E. B. Wilson, "Probable inference, the law of succession, and statistical inference," Journal of the American Statistical Association, vol. 22, no. 158, pp. 209-212, 1927.
63- A. Agresti and B. A. Coull, "Approximate is better than “exact” for interval estimation of binomial proportions," The American Statistician, vol. 52, no. 2, pp. 119-126, 1998.
64- C. S. Peirce, "The numerical measure of the success of predictions," Science, no. 93, pp. 453-454, 1884.
65- E. W. Steyerberg, B. Van Calster, and M. J. Pencina, "Performance measures for prediction models and markers: evaluation of predictions and classifications," Revista Española de Cardiología (English Edition), vol. 64, no. 9, pp. 788-794, 2011.
66- A. J. Vickers and E. B. Elkin, "Decision curve analysis: a novel method for evaluating prediction models," Medical Decision Making, vol. 26, no. 6, pp. 565-574, 2006.
67- G. W. Bohrnstedt and D. Knoke,"Statistics for social data analysis," 1982.
68- W. M. Rand, "Objective criteria for the evaluation of clustering methods," Journal of the American Statistical association, vol. 66, no. 336, pp. 846-850, 1971.
69- J. M. Santos and M. Embrechts, "On the use of the adjusted rand index as a metric for evaluating supervised classification," in International conference on artificial neural networks, 2009: Springer, pp. 175-184.
70- J. Cohen, "Weighted kappa: nominal scale agreement provision for scaled disagreement or partial credit," Psychological bulletin, vol. 70, no. 4, p. 213, 1968.
71- R. Bakeman and J. M. Gottman, Observing interaction: An introduction to sequential analysis. Cambridge university press, 1997.
72- S. Bangdiwala, "A graphical test for observer agreement," in 45th International Statistical Institute Meeting, 1985, vol. 1985, p. 307.
73- K. Bangdiwala and H. Bryan, "Using SAS software graphical procedures for the observer agreement chart," in Proceedings of the SAS Users Group International Conference, 1987, vol. 12, pp. 1083-1088.
74- A. F. Hayes and K. Krippendorff, "Answering the call for a standard reliability measure for coding data," Communication methods and measures, vol. 1, no. 1, pp. 77-89, 2007.
75- M. Aickin, "Maximum likelihood estimation of agreement in the constant predictive probability model, and its relation to Cohen's kappa," Biometrics, pp. 293-302, 1990.
76- N. A. Macmillan and C. D. Creelman, Detectiontheory: A user's guide. Psychology press, 2004.
77- D. J. Hand, P. Christen, and N. Kirielle, "F*: an interpretable transformation of the F-measure," Machine Learning, vol. 110, no. 3, pp. 451-456, 2021.
78- G. W. Brier, "Verification of forecasts expressed in terms of probability," Monthly weather review, vol. 78, no. 1, pp. 1-3, 1950.
79- L. Buitinck et al., "API design for machine learning software: experiences from the scikit-learn project," arXiv preprint arXiv:1309.0238, 2013.
80- R. W. Hamming, "Error detecting and error correcting codes," The Bell system technical journal, vol. 29, no. 2, pp. 147-160, 1950.
81- S. S. Choi, S. H. Cha, and C. C. Tappert, "A survey of binary similarity and distance measures," Journal of systemics, cybernetics and informatics, vol. 8, no. 1, pp. 43-48, 2010.
82- J. Braun-Blanquet, "Plant sociology. The study of plant communities," Plant sociology. The study of plant communities. First ed., 1932.
83- C. C. Little, "Abydos Documentation," 2020.
Cite
If you use PyCM in your research, we would appreciate citations to the following paper :
Haghighi, S., Jasemi, M., Hessabi, S. and Zolanvari, A. (2018). PyCM: Multiclass confusion matrix library in Python. Journal of Open Source Software, 3(25), p.729.
@article{Haghighi2018,
doi = {10.21105/joss.00729},
url = {https://doi.org/10.21105/joss.00729},
year = {2018},
month = {may},
publisher = {The Open Journal},
volume = {3},
number = {25},
pages = {729},
author = {Sepand Haghighi and Masoomeh Jasemi and Shaahin Hessabi and Alireza Zolanvari},
title = {{PyCM}: Multiclass confusion matrix library in Python},
journal = {Journal of Open Source Software}
}
Download PyCM.bib
| JOSS |  |
| Zenodo |  |
| Researchgate |  |
Show your support
Star this repo
Give a ⭐️ if this project helped you!
Donate to our project
If you do like our project and we hope that you do, can you please support us? Our project is not and is never going to be working for profit. We need the money just so we can continue doing what we do ;-) .

Changelog
All notable changes to this project will be documented in this file.
The format is based on Keep a Changelog and this project adheres to Semantic Versioning.
Unreleased
3.6 - 2022-08-17
Added
- Hamming distance
- Braun-Blanquet similarity
Changed
classesparameter added tomatrix_params_from_tablefunction- Matrices with
numpy.integerelements are now accepted - Arrays added to
matrixparameter accepting formats - Website changed to http://www.pycm.io
- Document modified
README.mdmodified
3.5 - 2022-04-27
Added
- Anaconda workflow
- Custom iterating setting
- Custom casting setting
Changed
plotmethod updatedclass_statisticsfunction modifiedoverall_statisticsfunction modifiedBCD_calcfunction modifiedCONTRIBUTING.mdupdatedCODE_OF_CONDUCT.mdupdated- Document modified
3.4 - 2022-01-26
Added
- Colab badge
- Discord badge
brier_scoremethod
Changed
J (Jaccard index)section inDocument.ipynbupdatedsave_objmethod updatedPython 3.10added totest.yml- Example-3 updated
- Docstrings of the functions updated
CONTRIBUTING.mdupdated
3.3 - 2021-10-27
Added
__compare_weight_handler__function
Changed
is_imbalancedparameter added to ConfusionMatrix__init__methodclass_benchmark_weightandoverall_benchmark_weightparameters added to Compare__init__methodstatistic_recommendfunction modified- Compare
weightparameter renamed toclass_weight - Document modified
- License updated
AUTHORS.mdupdatedREADME.mdmodified- Block diagrams updated
3.2 - 2021-08-11
Added
classes_filterfunction
Changed
classesparameter added tomatrix_params_calcfunctionclassesparameter added to__obj_vector_handler__functionclassesparameter added to ConfusionMatrix__init__methodnameparameter removed fromhtml_initfunctionshortenerparameter added tohtml_tablefunctionshortenerparameter added tosave_htmlmethod- Document modified
- HTML report modified
3.1 - 2021-03-11
Added
requirements-splitter.pysensitivity_indexmethod
Changed
- Test system modified
overall_statisticsfunction modified- HTML report modified
- Document modified
- References format updated
CONTRIBUTING.mdupdated
3.0 - 2020-10-26
Added
plot_test.pyaxes_genfunctionadd_number_labelfunctionplotmethodcombinemethodmatrix_combinefunction
Changed
- Document modified
README.mdmodified- Example-2 deprecated
- Example-7 deprecated
- Error messages modified
2.9 - 2020-09-23
Added
notebook_check.pyto_arraymethod__copy__methodcopymethod
Changed
averagemethod refactored
2.8 - 2020-07-09
Added
label_mapattributepositionsattributepositionmethod- Krippendorff's Alpha
- Aickin's Alpha
weighted_alphamethod
Changed
- Single class bug fixed
CLASS_NUMBER_ERRORerror type changed topycmMatrixErrorrelabelmethod bug fixed- Document modified
README.mdmodified
2.7 - 2020-05-11
Added
averagemethodweighted_averagemethodweighted_kappamethodpycmAverageErrorclass- Bangdiwala's B
- MATLAB examples
- Github action
Changed
- Document modified
README.mdmodifiedrelabelmethod bug fixedsparse_table_printfunction bug fixedmatrix_checkfunction bug fixed- Minor bug in
Compareclass fixed - Class names mismatch bug fixed
2.6 - 2020-03-25
Added
custom_rounderfunctioncomplementfunctionsparse_matrixattributesparse_normalized_matrixattribute- Net benefit (NB)
- Yule's Q interpretation (QI)
- Adjusted Rand index (ARI)
- TNR micro/macro
- FPR micro/macro
- FNR micro/macro
Changed
sparseparameter added toprint_matrix,print_normalized_matrixandsave_statmethodsheaderparameter added tosave_csvmethod- Handler functions moved to
pycm_handler.py - Error objects moved to
pycm_error.py - Verified tests references updated
- Verified tests moved to
verified_test.py - Test system modified
CONTRIBUTING.mdupdated- Namespace optimized
README.mdmodified- Document modified
print_normalized_matrixmethod modifiednormalized_table_calcfunction modifiedsetup.pymodified- summary mode updated
- Dockerfile updated
Python 3.8added to.travis.yamlandappveyor.yml
Removed
PC_PI_calcfunction
2.5 - 2019-10-16
Added
__version__variable- Individual classification success index (ICSI)
- Classification success index (CSI)
- Example-8 (Confidence interval)
install.shautopep8.sh- Dockerfile
CImethod (supported statistics :ACC,AUC,Overall ACC,Kappa,TPR,TNR,PPV,NPV,PLR,NLR,PRE)
Changed
test.shmoved to.travisfolder- Python 3.4 support dropped
- Python 2.7 support dropped
AUTHORS.mdupdatedsave_stat,save_csvandsave_htmlmethods Non-ASCII character bug fixed- Mixed type input vectors bug fixed
CONTRIBUTING.mdupdated- Example-3 updated
README.mdmodified- Document modified
CIattribute renamed toCI95kappa_se_calcfunction renamed tokappa_SE_calcse_calcfunction modified and renamed toSE_calc- CI/SE functions moved to
pycm_ci.py - Minor bug in
save_htmlmethod fixed
2.4 - 2019-07-31
Added
- Tversky index (TI)
- Area under the PR curve (AUPR)
FUNDING.yml
Changed
AUC_calcfunction modified- Document modified
summaryparameter added tosave_html,save_stat,save_csvandstatmethodssample_weightbug innumpyarray format fixed- Inputs manipulation bug fixed
- Test system modified
- Warning system modified
alt_linkparameter added tosave_htmlmethod andonline_helpfunctionCompareclass tests moved tocompare_test.py- Warning tests moved to
warning_test.py
2.3 - 2019-06-27
Added
- Adjusted F-score (AGF)
- Overlap coefficient (OC)
- Otsuka-Ochiai coefficient (OOC)
Changed
save_statandsave_vectorparameters added tosave_objmethod- Document modified
README.mdmodified- Parameters recommendation for imbalance dataset modified
- Minor bug in
Compareclass fixed pycm_helpfunction modified- Benchmarks color modified
2.2 - 2019-05-30
Added
- Negative likelihood ratio interpretation (NLRI)
- Cramer's benchmark (SOA5)
- Matthews correlation coefficient interpretation (MCCI)
- Matthews's benchmark (SOA6)
- F1 macro
- F1 micro
- Accuracy macro
Changed
Compareclass score calculation modified- Parameters recommendation for multi-class dataset modified
- Parameters recommendation for imbalance dataset modified
README.mdmodified- Document modified
- Logo updated
2.1 - 2019-05-06
Added
- Adjusted geometric mean (AGM)
- Yule's Q (Q)
Compareclass and parameters recommendation system block diagrams
Changed
- Document links bug fixed
- Document modified
2.0 - 2019-04-15
Added
- G-Mean (GM)
- Index of balanced accuracy (IBA)
- Optimized precision (OP)
- Pearson's C (C)
Compareclass- Parameters recommendation warning
ConfusionMatrixequal method
Changed
- Document modified
stat_printfunction bug fixedtable_printfunction bug fixedBetaparameter renamed tobeta(F_calcfunction &F_betamethod)- Parameters recommendation for imbalance dataset modified
normalizeparameter added tosave_htmlmethodpycm_func.pysplitted intopycm_class_func.pyandpycm_overall_func.pyvector_filter,vector_check,class_checkandmatrix_checkfunctions moved topycm_util.pyRACC_calcandRACCU_calcfunctions exception handler modified- Docstrings modified
1.9 - 2019-02-25
Added
- Automatic/Manual (AM)
- Bray-Curtis dissimilarity (BCD)
CODE_OF_CONDUCT.mdISSUE_TEMPLATE.mdPULL_REQUEST_TEMPLATE.mdCONTRIBUTING.md- X11 color names support for
save_htmlmethod - Parameters recommendation system
- Warning message for high dimension matrix print
- Interactive notebooks section (binder)
Changed
save_matrixandnormalizeparameters added tosave_csvmethodREADME.mdmodified- Document modified
ConfusionMatrix.__init__optimized- Document and examples output files moved to different folders
- Test system modified
relabelmethod bug fixed
1.8 - 2019-01-05
Added
- Lift score (LS)
version_check.py
Changed
colorparameter added tosave_htmlmethod- Error messages modified
- Document modified
- Website changed to http://www.pycm.ir
- Interpretation functions moved to
pycm_interpret.py - Utility functions moved to
pycm_util.py - Unnecessary
elseandelifremoved ==changed tois
1.7 - 2018-12-18
Added
- Gini index (GI)
- Example-7
pycm_profile.py
Changed
class_nameparameter added tostat,save_stat,save_csvandsave_htmlmethodsoverall_paramandclass_paramparameters empty list bug fixedmatrix_params_calc,matrix_params_from_tableandvector_filterfunctions optimizedoverall_MCC_calc,CEN_misclassification_calcandconvex_combinationfunctions optimized- Document modified
1.6 - 2018-12-06
Added
- AUC value interpretation (AUCI)
- Example-6
- Anaconda cloud package
Changed
overall_paramandclass_paramparameters added tostat,save_statandsave_htmlmethodsclass_paramparameter added tosave_csvmethod_removed from overall statistics namesREADME.mdmodified- Document modified
1.5 - 2018-11-26
Added
- Relative classifier information (RCI)
- Discriminator power (DP)
- Youden's index (Y)
- Discriminant power interpretation (DPI)
- Positive likelihood ratio interpretation (PLRI)
__len__methodrelabelmethod__class_stat_init__function__overall_stat_init__functionmatrixattribute as dictnormalized_matrixattribute as dictnormalized_tableattribute as dict
Changed
README.mdmodified- Document modified
LR+renamed toPLRLR-renamed toNLRnormalized_matrixmethod renamed toprint_normalized_matrixmatrixmethod renamed toprint_matrixentropy_calcfixedcross_entropy_calcfixedconditional_entropy_calcfixedprint_tablebug for large numbers fixed- JSON key bug in
save_objfixed transposebug insave_objfixedPython 3.7added to.travis.yamlandappveyor.yml
1.4 - 2018-11-12
Added
- Area under curve (AUC)
- AUNU
- AUNP
- Class balance accuracy (CBA)
- Global performance index (RR)
- Overall MCC
- Distance index (dInd)
- Similarity index (sInd)
one_vs_alldev-requirements.txt
Changed
README.mdmodified- Document modified
save_statmodifiedrequirements.txtmodified
1.3 - 2018-10-10
Added
- Confusion entropy (CEN)
- Overall confusion entropy (Overall CEN)
- Modified confusion entropy (MCEN)
- Overall modified confusion entropy (Overall MCEN)
- Information score (IS)
Changed
README.mdmodified
1.2 - 2018-10-01
Added
- No information rate (NIR)
- P-Value
sample_weighttranspose
Changed
README.mdmodified- Key error in some parameters fixed
OSXenv added to.travis.yml
1.1 - 2018-09-08
Added
- Zero-one loss
- Support
online_helpfunction
Changed
README.mdmodifiedhtml_tablefunction modifiedtable_printfunction modifiednormalized_table_printfunction modified
1.0 - 2018-08-30
Added
- Hamming loss
Changed
README.mdmodified
0.9.5 - 2018-07-08
Added
- Obj load
- Obj save
- Example-4
Changed
README.mdmodified- Block diagram updated
0.9 - 2018-06-28
Added
- Activation threshold
- Example-3
- Jaccard index
- Overall Jaccard index
Changed
README.mdmodifiedsetup.pymodified
0.8.6 - 2018-05-31
Added
- Example section in document
- Python 2.7 CI
- JOSS paper pdf
Changed
- Cite section
- ConfusionMatrix docstring
- round function changed to numpy.around
README.mdmodified
0.8.5 - 2018-05-21
Added
- Example-1 (Comparison of three different classifiers)
- Example-2 (How to plot via matplotlib)
- JOSS paper
- ConfusionMatrix docstring
Changed
- Table size in HTML report
- Test system
README.mdmodified
0.8.1 - 2018-03-22
Added
- Goodman and Kruskal's lambda B
- Goodman and Kruskal's lambda A
- Cross entropy
- Conditional entropy
- Joint entropy
- Reference entropy
- Response entropy
- Kullback-Liebler divergence
- Direct ConfusionMatrix
- Kappa unbiased
- Kappa no prevalence
- Random accuracy unbiased
pycmVectorErrorclasspycmMatrixErrorclass- Mutual information
- Support
numpyarrays
Changed
- Notebook file updated
Removed
pycmErrorclass
0.7 - 2018-02-26
Added
- Cramer's V
- 95% confidence interval
- Chi-Squared
- Phi-Squared
- Chi-Squared DF
- Standard error
- Kappa standard error
- Kappa 95% confidence interval
- Cicchetti benchmark
Changed
- Overall statistics color in HTML report
- Parameters description link in HTML report
0.6 - 2018-02-21
Added
- CSV report
- Changelog
- Output files
digitparameter toConfusionMatrixobject
Changed
- Confusion matrix color in HTML report
- Parameters description link in HTML report
- Capitalize descriptions
0.5 - 2018-02-17
Added
- Scott's pi
- Gwet's AC1
- Bennett S score
- HTML report
0.4 - 2018-02-05
Added
- TPR micro/macro
- PPV micro/macro
- Overall RACC
- Error rate (ERR)
- FBeta score
- F0.5
- F2
- Fleiss benchmark
- Altman benchmark
- Output file(.pycm)
Changed
- Class with zero item
- Normalized matrix
Removed
- Kappa and SOA for each class
0.3 - 2018-01-27
Added
- Kappa
- Random accuracy
- Landis and Koch benchmark
overall_stat
0.2 - 2018-01-24
Added
- Population
- Condition positive
- Condition negative
- Test outcome positive
- Test outcome negative
- Prevalence
- G-measure
- Matrix method
- Normalized matrix method
- Params method
Changed
statistic_resulttoclass_statparamstostat
0.1 - 2018-01-22
Added
- ACC
- BM
- DOR
- F1-Score
- FDR
- FNR
- FOR
- FPR
- LR+
- LR-
- MCC
- MK
- NPV
- PPV
- TNR
- TPR
- documents and
README.md
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pycm-3.6.tar.gz.
File metadata
- Download URL: pycm-3.6.tar.gz
- Upload date:
- Size: 481.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.10.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a0ba430d0b7fb35c70eaa956f7f7adb6c4fa3fa4f65372994281ac1ea45122aa
|
|
| MD5 |
cf1d220f9fb1b1b8e44c4d75b6441f83
|
|
| BLAKE2b-256 |
143c0037c160130425c6cf4e8bd2072f6024b553cad0a76c1db457cb622e07ca
|
File details
Details for the file pycm-3.6-py2.py3-none-any.whl.
File metadata
- Download URL: pycm-3.6-py2.py3-none-any.whl
- Upload date:
- Size: 64.2 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.10.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ebc8fe4804c0b244136f7e0c1375222d3a8f87b369bcade41366229b501f41bb
|
|
| MD5 |
06732e25eb37f9c3b31eee91c4c26e75
|
|
| BLAKE2b-256 |
c0646e1a57acd43fa4fb5171d996b68a9981e4f337c16cbc124f102f6cdc9a4c
|







