TSForecasting is an automated time series forecasting framework

Project description






TSForecasting: Automated Time Series Forecasting Framework
Framework Contextualization
The TSForecasting project offers a comprehensive and integrated pipeline designed to Automate Time Series Forecasting applications. By implementing multivariate approaches that incorporate multiple regression models, it combines varied relevant modules such as SKLearn, AutoGluon, CatBoost and XGBoost, following an Expanding Window structured approach for performance evaluation ensuring a robust, scalable and optimized forecasting solution.
The architecture design includes five main sections: data preprocessing, feature engineering, hyperparameter optimization, model evaluation and forecasting, which are organized and customizable in a pipeline structure.
This project aims at providing the following application capabilities:
-
General applicability on tabular datasets: The developed forecasting procedures are applicable on any data table associated with any Time Series Forecasting scopes.
-
Hyperparameter optimization and customization: It provides full configuration for each model hyperparameter through the customization of
model_configurationsdictionary, allowing optimal performance to be obtained for any use case. -
Robustness and improvement of predictive results: The implementation of the TSForecasting pipeline aims to improve the predictive performance directly associated with the application of the best performing forecasting method.
-
Prediction intervals with multiple methods: Four coverage levels (80%, 90%, 95%, 99%) with four estimation methods (ensemble, quantile, conformal, gaussian) for robust uncertainty quantification.
Main Development Tools
Major frameworks used to build this project:
Performance Evaluation Structure
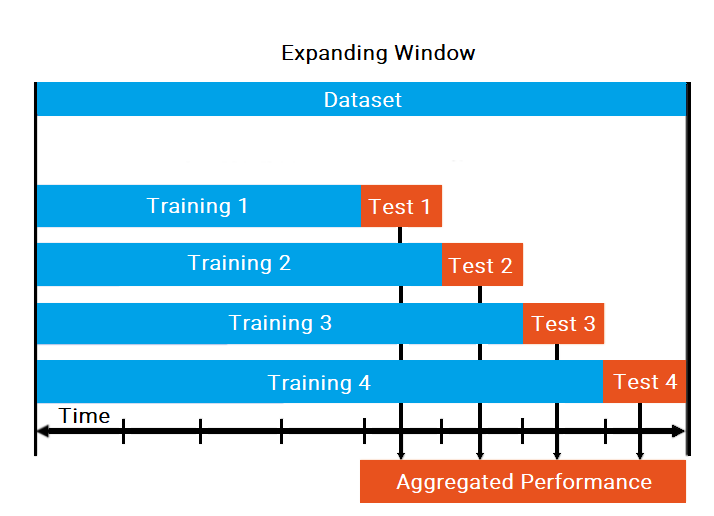
The Expanding Window evaluation technique provides a temporal approximation of the real value of time series data. The first test segment is selected according to the train length and then forecasted in accordance with the forecast horizon. The starting position of each subsequent segment is set in direct relation to the sliding window size - if the sliding size equals the forecast size, each segment starts at the end of the previous one. This process repeats until all time series data is segmented, using all iterations and observations to construct an aggregated and robust performance analysis for each predicted point.
Where to get it
Binary installer for the latest released version is available at the Python Package Index (PyPI).
Installation
To install this package from Pypi repository run the following command:
pip install tsforecasting
Usage Examples
1. TSForecasting - Automated Time Series Forecasting
The first step after importing the package is to load a dataset and define your DateTime (datetime64[ns] type) and Target column to be predicted, then rename them to Date and y, respectively.
The pipeline follows a straightforward workflow: configure parameters, fit the model across expanding windows, evaluate performance, and generate forecasts with prediction intervals. The fit_forecast method trains and evaluates all selected models using the expanding window approach, automatically selecting the best performer. The history method returns detailed performance metrics across all windows and horizons, while forecast generates future predictions using the best model.
Pipeline Parameters:
train_size: Proportion of data used for the initial training window (0.3 to 0.95)lags: Number of lag features (window size) - how many past observations each input sample includeshorizon: Number of future time steps to forecastsliding_size: Window expansion size per iteration (sliding_size >= horizonrecommended)models: List of models to evaluate. Available options:RandomForest,ExtraTrees,GBR,KNN,GeneralizedLRXGBoost,Catboost,AutoGluon
hparameters: Nested dictionary containing model-specific hyperparameter configurations (customizable viamodel_configurations())granularity: Time frequency of the data -1m,30m,1h,1d,1wk,1mo(default:1d)metric: Evaluation metric for model selection -MAE,MAPE, orMSE(default:MAE)
import warnings
import pandas as pd
from tsforecasting import TSForecasting, model_configurations
warnings.filterwarnings("ignore", category=Warning)
# Load and prepare data
data = pd.read_csv("your_timeseries.csv")
data = data.rename(columns={"DateTime_Column": "Date", "Target_Column": "y"})
data["Date"] = pd.to_datetime(data["Date"])
data = data[["Date", "y"]]
# Get and customize model hyperparameters
hparameters = model_configurations()
hparameters["RandomForest"]["n_estimators"] = 100
hparameters["XGBoost"]["n_estimators"] = 100
hparameters["Catboost"]["iterations"] = 100
# Configure and fit pipeline
tsf = TSForecasting(
train_size=0.80,
lags=10,
horizon=10,
sliding_size=10,
models=[
"RandomForest",
"ExtraTrees",
"GBR",
"KNN",
"XGBoost",
"Catboost",
],
hparameters=hparameters,
granularity="1d",
metric="MAE",
)
tsf.fit_forecast(dataset=data)
# Get performance history
history = tsf.history()
print(f"Best Model: {tsf.selected_model}")
# Generate forecast with prediction intervals
forecast = tsf.forecast()
print(forecast[["Date", "y", "y_lower_90", "y_upper_90"]])
Performance Analysis
The history() method returns a PerformanceHistory dataclass containing detailed evaluation results essential for analyzing forecasting performance across models, windows, and horizons.
# Access history components
history = tsf.history()
# 1. Predictions DataFrame - Raw forecasts per window with timestamps
predictions = history.predictions
print(f"Shape: {predictions.shape}")
print(predictions.head())
# Columns: Date, y_horizon_1..N, y_forecast_horizon_1..N, Window, Model
# 2. Complete Performance - Detailed metrics per window and horizon
performance_complete = history.performance_complete
print(performance_complete.head(10))
# Columns: Model, Window, Horizon, MAE, MAPE, MSE, Max Error
# 3. Performance by Horizon - Aggregated metrics across windows per horizon
performance_horizon = history.performance_by_horizon
print(performance_horizon)
# Useful for understanding error growth over forecast horizon
# 4. Leaderboard - Model rankings by selected metric
leaderboard = history.leaderboard
print(leaderboard.to_string(index=False))
# Models ranked by mean performance across all windows
# 5. Selected Model
print(f"Best Model: {history.selected_model}")
2. Builder Pattern (Alternative Configuration)
For more readable configuration, use the fluent builder pattern:
from tsforecasting import TSForecastingBuilder
tsf = (TSForecastingBuilder()
.with_train_size(0.80)
.with_lags(10)
.with_horizon(10)
.with_sliding_size(10)
.with_models(['RandomForest', 'XGBoost'])
.with_granularity('1d')
.with_metric('MAE')
.with_preprocessing(scaler='robust', datetime_features=True)
.build())
tsf.fit_forecast(dataset=data)
forecast = tsf.forecast()
3. Prediction Intervals
TSForecasting generates prediction intervals at four fixed coverage levels: 80%, 90%, 95%, and 99%. Four estimation methods are available:
| Method | Description | Best For |
|---|---|---|
ensemble |
Average of all three methods (default) | General use, most robust |
quantile |
Empirical percentiles of residuals | Asymmetric error distributions |
conformal |
Distribution-free coverage guarantee | Theoretical guarantees |
gaussian |
Parametric normal assumption | Symmetric, well-behaved errors |
Mathematical Formulations:
-
Quantile: Computes empirical percentiles of historical residuals (
lower = forecast + percentile(residuals, α/2)). Captures asymmetric errors without distributional assumptions. -
Conformal: Uses absolute errors as nonconformity scores with finite-sample correction. Provides coverage guarantees with symmetric, constant-width intervals.
-
Gaussian: Assumes normally distributed residuals (
lower = forecast + bias - z × std). Efficient and accounts for systematic bias. -
Ensemble (Default): Averages bounds from all three methods, balancing their strengths for robust uncertainty estimates.
# Default: ensemble method (recommended)
forecast = tsf.forecast()
# Specific methods
forecast = tsf.forecast(interval_method="quantile")
forecast = tsf.forecast(interval_method="conformal")
forecast = tsf.forecast(interval_method="gaussian")
4. Auxiliary Methods
Processing - Time Series Transformation
The make_timeseries method transforms a DataFrame into a supervised learning format ready for time series analysis:
window_size: Number of past observations (lags) each sample includeshorizon: Number of future time steps to predictdatetime_engineering: Enriches dataset with date-time features (year, month, day of week, etc.)
from tsforecasting import Processing
processor = Processing()
timeseries = processor.make_timeseries(
dataset=data,
window_size=10,
horizon=5,
datetime_engineering=True
)
TreeBasedFeatureSelector - Feature Selection
Select most relevant features based on tree-based importance:
from tsforecasting import TreeBasedFeatureSelector
selector = TreeBasedFeatureSelector(
algorithm='ExtraTrees', # RandomForest, ExtraTrees, GBR
relevance_threshold=0.95, # Keep features explaining 95% of variance
n_estimators=100
)
selector.fit(X, y)
X_selected = selector.transform(X)
print(selector.selected_features)
Detailed Timeseries Examples
TSForecasting Guideline Examples
Interactive Notebooks
For a more interactive experience, feel free to explore the Jupyter notebooks with step-by-step execution and guidelines:
Citation
If you use TSForecasting in your research, please cite:
@software{tsforecasting,
author = {Luis Fernando Santos},
title = {TSForecasting: Automated Time Series Forecasting Framework},
year = {2022},
url = {https://github.com/TsLu1s/TSForecasting}
}
License
Distributed under the MIT License. See LICENSE for more information.
Contact
Luis Santos - LinkedIn
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file tsforecasting-1.61.20-py3-none-any.whl.
File metadata
- Download URL: tsforecasting-1.61.20-py3-none-any.whl
- Upload date:
- Size: 44.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
03ab618d358287d82db823e20a7d38338bc1ba2ebe4feb8a74e9243205e67da3
|
|
| MD5 |
094d5c85a4eb955d8ce6b296a6a78fba
|
|
| BLAKE2b-256 |
3ba29d1844e2c5d407177dd7f711e906b6758b3cb918d9e9dafbaed24d7e628f
|







